Reinforcement Learning : Theory and the CartPole game
What is Reinforcement Learning ?
Introduction
This will basically serve as a toolbox / summary of what I’ve learned about Reinforcement Learning either throughout the course or with my own exploration.
I was extremely excited witht the idea of learning more about Reinforcement Learning : ever since I discovered the potential of Artficial Intelligence and Machine Learning, I was blown away by how people were actually programming AI to play games. It looked exciting and fun, and I believe that it is the easiest Machine Learning paradigm to explain to neophytes. Reinforcement Learning is pretty similar to trying to teach your pet a trick : if it succeeds you can give it a reward, otherwise you try again !
Well, obviously, there’s more that meets the eye but the basics are here, you learn through trial and error and try to make your agent the best ever. If you’re good at it you might end up working with OpenAI but we’re not quite there yet. Let’s get into terminoly and basics of what I currently know.
Terminology
Okay, to kick things off we need a bit of terminology. There are a lot of things interacting in a Reinforcement Learning method :
-
The agent : This is the entity that will learn and take decisions
-
The environment : The “situation” in which the agent learn and takes decision
-
The action : The set of possibles doings for the agent
-
The state : The “position” of the agent in the environment
-
The reward : For a certain state of the agent, the environment provides a reward to the agent
-
The policy : The decision making function, which maps situations and actions
-
The value function : Maps states to real numbers, where the value of a state represents the long-term reward achieved starting from that state, and executing a particular policy.
-
The model : The agent’s view of the environment, which maps state-action pairs to probability distributions over states.
If we understand each and every point of this we’re nearly set to take on our first Reinforcement Learning problem. What should be said is that even the most complex RL AIs like AlphaZero for Chess or AlphaGo for Go both follow the same principles, they require ton of computing capabilities but are now able to consistantly defeat the best players. AlphaZero for example only needed 4 hours of training to absolutely demolish what was considered the strongest Chess Entity : StockFish… Let’s see how we can perform regarding the CartPole problem !
Cart Pole lab
The Cart Pole, is part of OpenAI’s gym : a database of problems meant to evaluate and compete on Machine Learning problems. The Cart Pole is a simple problem : the cart pole is a pendulum with a center of gravity above its pivot point. It’s unstable, but can be controlled by moving the pivot point under the center of mass. The goal is to keep the cartpole balanced by applying appropriate forces to a pivot point. If the cart goes too far right or left, or if the pole angle is larger than 12 degrees the “game” is considered to be lost.
Our goal is to use a Deep Q Neural Network to train our agent to have the best score possible. Q-learning learns the action-value function Q(s, a): how good to take an action at a particular state. Basically a scalar value is assigned over an action a given the state s and Deep Q Neural Network uses a neural network that will approximate Q-values for each action based on the state.
For our network to be considered successfull we’ll need to get a mean score of 195 for an agent.
The code structure
Let’s try and understand the code structure for this lab:
-
Q Network Class : This class is defining the Q value function with a neural network. The layers are linear and the output layer is a fully connected one. The overall output is a tensor that will help the agent determine which is the best action to perform based on the state he’s in.
-
The Doer : This class determines the action that’s gonna be accomplished by the agent. It takes the maximum value from the previously defined tensor and performs the associated action (either 1 or 0)
-
The Experience Replay : This class keeps track of all the transitions that have occured during the training and they way they are used to further improve the model’s results
-
The Learner : Uses the information provided by the experience replay to train the train the network
-
The Evaluation and The Renderer : The first is to evaluate the model by displaying the mean score for each episode and the other allows us to visually evaluate how our model is behaving
Understanding parameters
There are a few parameters that we are going to be able to tweak in order to achieve and build a successful model. From what I’ve understood here are the ones we can change and their respective impact :
– Width of the network : basically referring to the size of a layer
– Number of hidden layers : pretty straightforward…
– Activation function : as in regular Marchine Learning
– The droupout rate" : Same as in regular Machine Learning, how much neurons in proportion, are going to be thrown away to reduce overfitting
– Espsilon : For the Doer it refers to the proportion of random behaviour that will be induced
– Buffer size : The number of transition that the system considers at every step
– Weighted batches : Do we choose the most relevant transitions (lower loss) or do we choose them uniformally ?
Initial results :
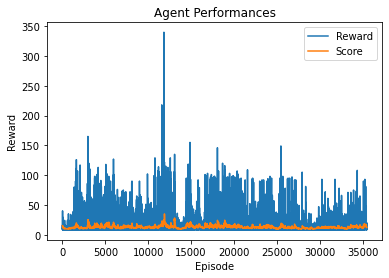
Already implemented parameters
Tweaking tests :
– Width of the network : 256
– Number of hidden layers : 4
– Activation function : Sigmoid
– The droupout rate" : 0.2
– Espsilon : 0.2
– Buffer size : 512
– Batch size : 128
– Weighted batches : True
– Optimizer : SGD
– Algorithm : QLearning
With this implementation I was able to retrieve more positive results : Score got up to 25 sometimes. But I could not figure out a satisfying way to get a value above 50. Either I messed up on my preparation or I’ve missed a crucial part.
Obviously, it’s a lot of hyperparameters to tweek, considering the task, so I went in here trying to find a more suitable option, the problem is that with all the structures that I’ve had, my maximum value looks like a wall. My algortihm does not seem to be capable of learning above that limit… Thus, the incompletion in my results.
I’m sorry I could not try and tweak with other parameters, I’ve like I’ve come to a pretty good understanding of the lab and the finding of the perfect parameters.
Course feedback and overall feelings
As a chess enthusiast, I was thrilled at the idea of discovering of how algorithms such as AlphaZero work. I was not disappointed with the content of the course. It was great having you as our teacher since you seemed so passionate and really pedagogue.
I would have wanted maybe to try and implement my “own” network in a lab, but the one that we had made me realise how different and complicated this process might be. Furthermore, it was hard on the machine side to be efficient with the Google Collab, and I’m sorry if you feel like I have not dedicated as much time as I should have.
Overall, I feel like I’ve theoritically learned a lot, understood a lot aswell ; and I feel confident to try and build something on the Reinforcement Learning side as for now.
Thank you very much for your time and attention !