Recurrent Neural Networks
Introduction
During this course, I had the pleasure of discovering what Recurrent Neural Networks were. Since the evaluation associated to this course is mostly based on my understanding on the course, I’ll try and be the clearest possible to show how much I’ve learned.
Sequence Modelling
As said in the course, sequential data is everywhere. Wether in stock exchange data, music, texts, proteines, audio etc. What we mean by sequence is an enumeration of possibly repeated objects. And a specific order in the sequence leads to a specific result : a different sequence of amino acids will lead to a different protein.
The question is : Can you use a Feed Forward Neural Network to complete classification over what we defined as a sequence ? The answer is no. Because of the variable size of the input (we need it to be fixed..) a regular FFNN would lead to incorrect predictions if the right architecture is not chosen, it would suffer from not having good generalisation and thus we would endlessly have to readapt our structure to make it fit for tiny different problems.
Sequence Modelling is thus the ability of a network, to make predictions about any type of sequential data. Google Trad is a perfect example of a model that is able to handle sequential data.
Recurrent Neural Networks
Reuccrent Neural Networks are able to handle variable length of inputs and outputs, preserve sequential information and have a good generalisation.
But even if they are different than the regular Feed Forward Neural Network, they are still inspired by the human brain.
Behaving in the same way that our brain, RNN take into account all of what’s has been fed to him through a recurrent relation : h !
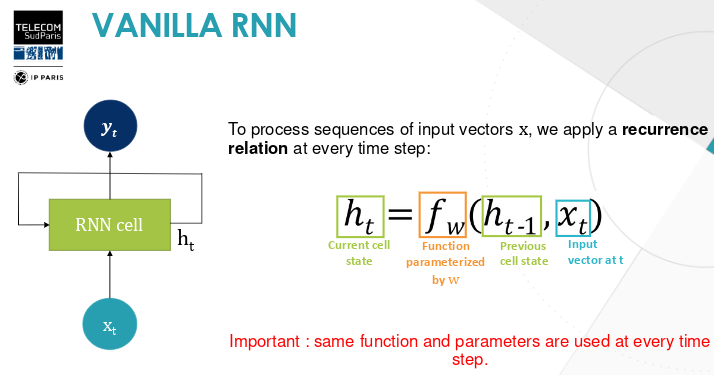
Basic architecture
Basically the RNN is going to take into account through each time step the information about previous time steps, therefore the network keeps in memory everything that passes as a human brain would do.
In RNN we still need as in regular NN to minimise the loss in order to improve accuracy. To do so, weights are not updated at each time step but in the end ! To do so, RNN use a backpropagation through time. The system basically goes back in time (ie the sequence) and backpropagates the error like in a NN. But the BPTT is more complex than the regular one because it akes into account all of the previous steps in time. For simple models like the Vanilla one, Gradient Explosion & Gradient Vanishing are thus very common because of the computing complexity.
These problems with the gradient mainly come with the fact that long sequence may encapsluate the missing information in the very first part of the sequence. To retrieve it would mean that the RNN must not loose any information throughout its whole computation which is mostly impossible. To solve this issue, LSTM or Long Short Term Memory Networks are used.
LSTM
Instead of having just one neuron in the repeating module, LSTM have four which aim to help with long-term dependencies.
These four “neurons” or gates filter information, by forgetting it or deciding what to write, or how much to write and what to output. Basically they are behaving as a human brain would do, trying to remember the most accurate and useful information. This solution solves in practive the problems faced with the gradient.
Applications
RNN are used in various fields, Language Modelling (Predicting the last word of a sentence), Image Generation (trying to predict the next image in a sequence), Sequence to Sequence (translation for example), Visual Question Answering (outputting information about a given picture), Hand Gesture Recognition etc.
The main problem with RNN is that they need to wait until all the data has been proceeded before being able to make a prediction…
But this field is particularly exciting mostly with the topic of Attention : The idea is to let every step of an RNN pick information to look at from some larger collection of information. For example, if you are using an RNN to create a caption describing an image, it might pick a part of the image to look at for every word it outputs.
The ideas of style transfer and its unlimited potential truly highlight how important RNN might become in art, culture or something we might even not know yet…
The lab
Unfortunately, I could not quite finish the lab 😢 …
So I’ve decided to focus on the explanation of my understanding of the course.
To make up for the lab uncompletion I would like to give you some feedback about the course.
I’ve enjoyed a lot discovering another aspect of AI, mostly because I did not know about RNN or at least the basic concept behind it.
You were really pedagogue and enthusiatic and I thank you for that.